
지난 화 핵심
컴퓨터는 글자를 이해 못하니 수치화하고 범위를 데이터 스케일링(조절)해야 한다.
컴퓨터가 이해할 수 있는 데이터를 모델에 넣어서 데이터 예측 결괏값이 나온다.
머신러닝에서 조심해야 할 부분 중 하나!
모델을 만들어서 데이터를 만들 때 예측하는 것이지,
너무 오버하면 일반화시키지 못한다.
즉, 너무 훈련 데이터에만 하면 안 된다는 의미!
underfitting(언더피팅)
트레이닝이 제대로 안돼서 성능이 안 나올 때
overfitting(오버피팅)
너무 샘플데이터로만 맞추려고 할 때
머신러닝 기법 (알고리즘)
1. KNN (최근접 이웃)
K는 이웃의 숫자를 의미한다.

새로운 데이터가 들어왔을 때 주변 이웃으로 판단하는 것.
(출처 : https://www.datacamp.com/community/tutorials/k-nearest-neighbor-classification-scikit-learn)
KNN에서는 데이터와 데이터 사이의 거리를 구해야 하는데,
이때 거리를 구하는 방식은 두 가지가 있다.
1. 유클리드 거리 (Euclidean Distance)
일반적으로 점과 점 사이의 거리를 구하는 것

2. 맨해튼 거리 (Manhattan Distance)

x축과 y축을 따라간 거리
'맨해튼 시내에는 빌딩이 많아 A->B로 이동할 때 격자 모양의 길을 따라가야 한다.' 라고 해서 생겨남
2. Decision tree (결정트리)

의사 결정 트리로, 의사 결정 분석에서 목표에 가장 가까운 결과를 낼 수 있는 전략을 찾기 위해 주로 사용되는 기법
(출처 https://medium.com/@chiragsehra42/decision-trees-explained-easily-28f23241248)
3. Ramdom Forest (랜덤 포레스트)
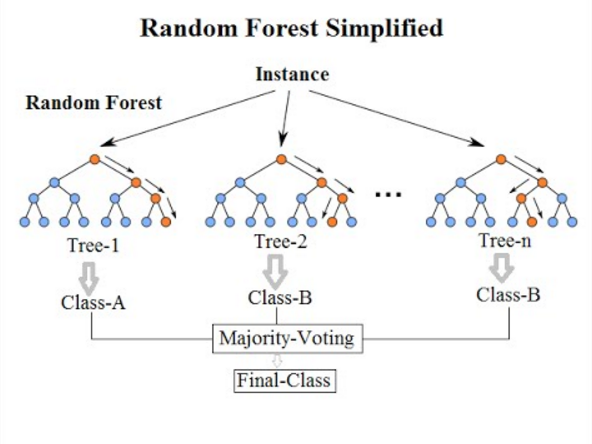
랜덤 포레스트는 앙상블 기법 중 하나로,
학습된 데이터의 decision tree를 모두 돌려서, 그 결과를 확인하는 것이다.
(출처 https://medium.com/@williamkoehrsen/random-forest-simple-explanation-377895a60d2d)
앙상블 기법
통계학과 기계학습에서 앙상블 학습법은 학습 알고리즘(arning algorithm)들을 따로 쓰는 경우에 비해 더 좋은 예측 성능을 얻기 위해 다수의 학습 알고리즘을 사용하는 방법으로, 여러 개의 모델을 학습시켜 예측 결과를 이용해서 하나의 모델보다 더 나은 예측 성능을 얻기 위해 사용하는 방법이다.
4. SVM (support vector machine, 서포트 벡터 머신)

가운데 선을 결정선 바운더리라고 하는데, 두 가지 특징 중 가장 가까운 두 개가 있다면 선택하고 걔 중 먼 곳에 선을 긋는다.
패턴 인식, 자료 분석을 위한 지도 학습 모델이며, 주로 분류와 회귀 분석을 위해 사용한다.
(출처 https://ko.wikipedia.org/wiki/%EC%84%9C%ED%8F%AC%ED%8A%B8_%EB%B2%A1%ED%84%B0_%EB%A8%B8%EC%8B%A0)
XGboost (XG부스트)
XGBoost는 Gradient Boosting 알고리즘을 분산 환경에서도 실행할 수 있도록 구현해놓은 라이브러리이다.
(출처: https://bcho.tistory.com/1354)
끄적
모델은 일반화가 중요하다
cross_val_score
Testing
elf = SVC()
# clf.fit 를 이용하면 끝..
clf.fit(train_date, target)
test_data = test.drpo(“Passengerld”, axis=1).copy()
prediction = clf.predict(test_data)
clf.predict ( 예측 )
'IT > 기록' 카테고리의 다른 글
| NodeJS에서 엑셀 파일 읽고 쓰기! #1 (0) | 2021.06.01 |
|---|---|
| React Native에서 사용자 로그인 상태 유지는 어떻게? (0) | 2021.05.28 |
| 머신러닝. 01 (0) | 2020.09.15 |
| 고객 세분화 (0) | 2020.09.15 |
| 웹 크롤링 기록 (0) | 2020.09.15 |